2. How Search Engines Identify Duplicate Content
Some examples will illustrate the process for Google as it finds
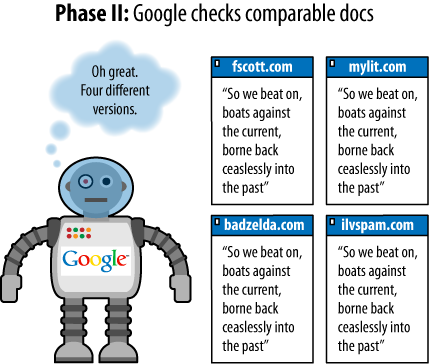
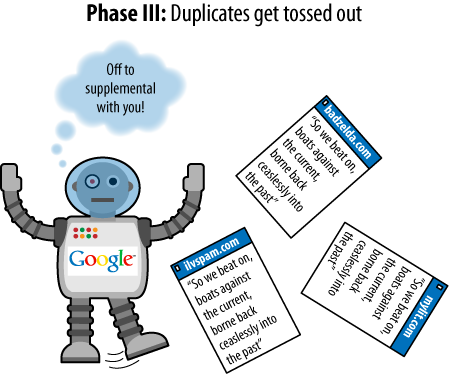
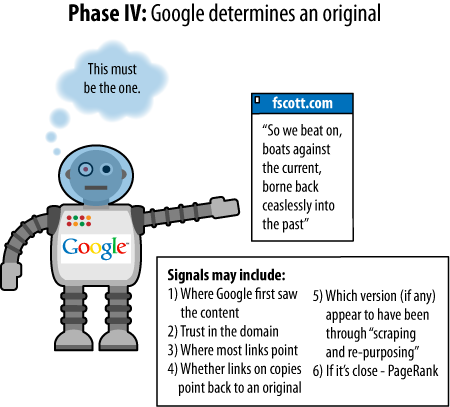
duplicate content on the Web. In the examples shown in Figures Figure 1 through Figure 4, three assumptions have been
made:
The page with text is assumed to be a page containing
duplicate content (not just a snippet, despite the
illustration).
Each page of duplicate content is presumed to be on a separate
domain.
The steps that follow have been simplified to make the process
as easy and clear as possible. This is almost certainly not the
exact way in which Google performs (but it conveys the
effect).

There are a few facts about duplicate content that bear mentioning
as they can trip up webmasters who are new to the duplicate content
issue:
Location of the duplicate content
Is it duplicated content if it is all on my site? Yes, in
fact, duplicate content can occur within a site or across
different sites.
Percentage of duplicate content
What percentage of a page has to be duplicated before you
run into duplicate content filtering? Unfortunately, the search
engines would never reveal this information because it would
compromise their ability to prevent the problem.
It is also a near certainty that the percentage at each
engine fluctuates regularly and that more than one simple direct
comparison goes into duplicate content detection. The bottom line
is that pages do not need to be identical to be considered
duplicates.
Ratio of code to text
What if your code is huge and there are very few unique HTML
elements on the page? Will Google think the pages are all
duplicates of one another? No. The search engines do not really
care about your code; they are interested in the content on your
page. Code size becomes a problem only when it becomes
extreme.
Ratio of navigation elements to unique content
Every page on my site has a huge navigation bar, lots of
header and footer items, but only a little bit of content; will
Google think these pages are duplicates? No. Google (and Yahoo!
and Bing) factor out the common page elements such as navigation
before evaluating whether a page is a duplicate. They are very
familiar with the layout of websites and recognize that permanent
structures on all (or many) of a site’s pages are quite normal.
Instead, they’ll pay attention to the “unique” portions of each
page and often will largely ignore the rest.
Licensed content
What should I do if I want to avoid duplicate content
problems, but I have licensed content from other web sources to
show my visitors? Use meta name =
"robots" content="noindex, follow". Place this in your
page’s header and the search engines will know that the content
isn’t for them. This is a general best practice, because then
humans can still visit the page, link to it, and the links on the
page will still carry value.
Another alternative is to make sure you have exclusive
ownership and publication rights for that content.